庖丁解LevelDB之?dāng)?shù)據(jù)存儲 數(shù)據(jù)處理與存儲支持服務(wù)深度剖析
LevelDB作為Google開源的輕量級鍵值存儲引擎,以其高效、可靠的存儲特性被廣泛應(yīng)用于各類系統(tǒng)中。其數(shù)據(jù)存儲機制猶如庖丁解牛,精準(zhǔn)而高效。本文將深入剖析LevelDB的數(shù)據(jù)處理流程與存儲支持服務(wù),揭示其內(nèi)部運作的精妙設(shè)計。
一、數(shù)據(jù)寫入流程:從日志到持久化
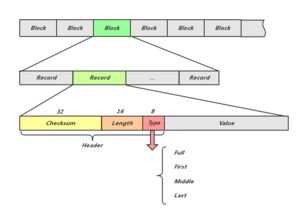
LevelDB的數(shù)據(jù)寫入遵循“先寫日志,后寫內(nèi)存表”的原則,確保數(shù)據(jù)的持久性與一致性。當(dāng)寫入請求到達時,系統(tǒng)首先將操作記錄追加到Write-Ahead Log(WAL)中,即使后續(xù)進程崩潰,數(shù)據(jù)也能通過日志恢復(fù)。數(shù)據(jù)被插入到內(nèi)存中的MemTable(基于跳表實現(xiàn)),提供快速的讀寫訪問。這種設(shè)計兼顧了性能與安全,是LevelDB高可靠性的基石。
二、內(nèi)存與磁盤的協(xié)同:MemTable與SSTable
MemTable作為內(nèi)存數(shù)據(jù)結(jié)構(gòu),容量有限。當(dāng)達到閾值時,LevelDB會將其凍結(jié)為Immutable MemTable,并異步壓縮轉(zhuǎn)換為磁盤上的Sorted String Table(SSTable)。SSTable按鍵排序存儲,支持高效的范圍查詢。LevelDB通過分層(Level)組織SSTable,并利用Compaction過程合并和清理舊數(shù)據(jù),平衡讀寫放大問題。這種分級存儲策略,實現(xiàn)了數(shù)據(jù)在內(nèi)存與磁盤間的動態(tài)流轉(zhuǎn)。
三、存儲支持服務(wù):緩存、索引與壓縮
LevelDB內(nèi)置多項存儲支持服務(wù)以優(yōu)化性能。Block Cache緩存頻繁訪問的磁盤數(shù)據(jù)塊,減少I/O開銷;Bloom Filter作為概率索引,快速判斷鍵是否存在于SSTable中,避免不必要的磁盤掃描;Snappy壓縮算法則減小存儲空間,提升傳輸效率。這些服務(wù)協(xié)同工作,共同構(gòu)建了一個高效、低延遲的存儲環(huán)境。
四、故障恢復(fù)與一致性保障
LevelDB通過Manifest文件記錄元數(shù)據(jù)變更(如SSTable層級信息),結(jié)合WAL日志,確保系統(tǒng)在崩潰后能恢復(fù)到一致狀態(tài)。Compaction過程采用漸進式策略,避免長時間阻塞,同時通過版本控制管理數(shù)據(jù)快照,支持多線程并發(fā)訪問。這些機制保障了數(shù)據(jù)在復(fù)雜場景下的完整性與可用性。
精雕細琢的存儲藝術(shù)
LevelDB的數(shù)據(jù)存儲設(shè)計,體現(xiàn)了對細節(jié)的極致追求。從日志持久化到分層壓縮,從緩存加速到故障恢復(fù),每個環(huán)節(jié)都經(jīng)過精心優(yōu)化。正如庖丁解牛,其核心在于深刻理解數(shù)據(jù)流動的脈絡(luò),以簡潔的架構(gòu)解決復(fù)雜的存儲挑戰(zhàn)。對于開發(fā)者而言,掌握這些原理不僅能更好地應(yīng)用LevelDB,也能為設(shè)計高性能存儲系統(tǒng)提供寶貴借鑒。
如若轉(zhuǎn)載,請注明出處:http://www.huliduo.net.cn/product/62.html
更新時間:2026-06-07 16:41:06